Chapter 1
据小伙伴说,这本书去年还挺火的Designing Data-Intensive Applications. 最近闲来无聊读读看看。
前言加第一章一般都是预热章节, 给一个high level idea. 作者聊聊这书给谁看的。挺有意思的。 第一章就是讲什么是 Reliability,Scalability,Maintainability
放上chapter章尾的summay:
-
Reliability means making systems work correctly, even when faults occur. Faults can be in hardware (typically random and uncorrelated), software (bugs are typically sys‐ tematic and hard to deal with), and humans (who inevitably make mistakes from time to time). Fault-tolerance techniques can hide certain types of faults from the end user.
-
Scalability means having strategies for keeping performance good, even when load increases.
-
Maintainability 就是说好好写代码,好好维护。。。
Chapter 2
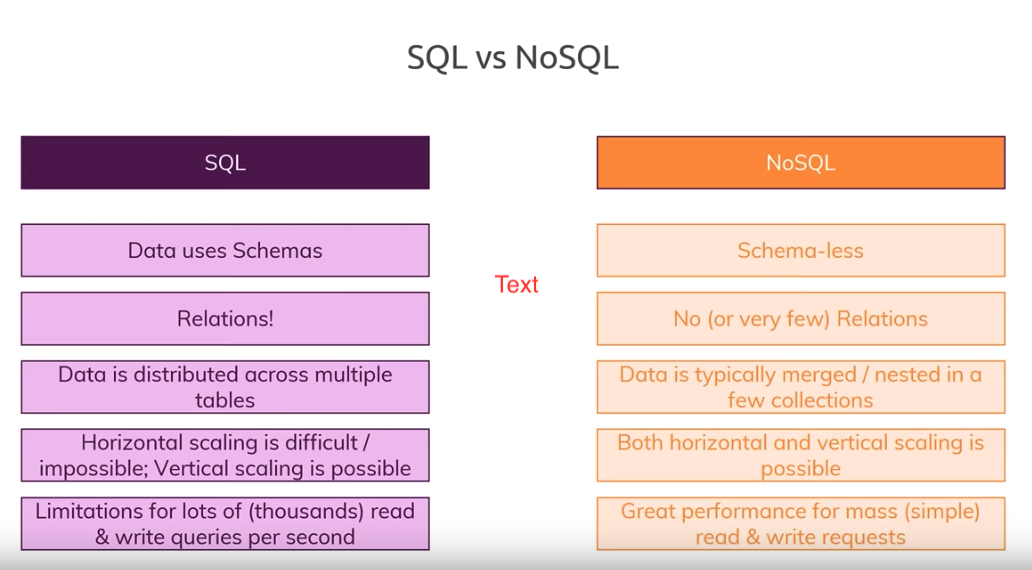
这章主要讲了3种database 类型
NoSQL
- Document databases target use cases where data comes in self-contained documents and relationships between one document and another are rare.
- Graph databases go in the opposite direction, targeting use cases where anything is potentially related to everything.
SQL
- Relation database
这有一个youtube video 对比NoSQL和SQL.简单明了。 图片也是摘自该视频。 当需要存储大量多对多的关系,SQL更新起来比较方便,NoSQL这种情况下可能需要重复更新一些值。但是如果是大量的读操作,如果SQL需要join很多表的话,那么这时候NoSQL可能更好一点。 所以不能简单说哪种类型的数据库更好, 需要看被处理的数据类型和load。
Chapter 3
这章主要讲数据的存储与索引:
OLAP 与 OLTP
OLTP systems are typically user-facing, which means that they may see a huge volume of requests. In order to handle the load, applications usually only touch a small number of records in each query. OLAP are optimized for analytics
OLAP 数据库索引
Column-Oriented Storage 列存储
中间讲了列压缩
OLTP 数据库索引
Hash indexes
-
Introduce hash indexes Keep an in-memory hash map where every key is mapped to a byte offset in the data file—the location at which the value can be found
-
use case : Bitcask (the default storage engine in Riak)
- how do we avoid eventually running out of disk space?
- compaction: merge several segments into one and discard the old data.
-
advantages:
-
Appending and segment merging are sequential write operations, which are gen‐ erally much faster than random writes
-
oncurrency and crash recovery are much simpler if segment files are append- only or immutable.
-
Merging old segments avoids the problem of data files getting fragmented over time.
-
-
disadvantages:
-
The hash table must fit in memory, not good if we have a very large number of keys
-
Range queries are not efficient. need to scan each key individually.
-
为了改进以上的缺点,整了个LSM tree 和B tree出来。 首先我们需要看一下什么叫 Sorted String Table(SSTable) : sorted key-value pairs 和其优点(相对于无序追加):
- Merging segments is simple and efficient
- Don’t need to keep an index of all the keys in memory since it is sorted by key.
- compression data first and wirte to dish will reduce I/O bandwidth use
LSM-tree
- Introduce LSM: LSM is short for Log-Structured Merge-Tree. 这有一个blog讲的很清楚。 写的大致原理就是,它 consists of two MemTables in main memory and a set of SSTables. 当有数据来的时候,先放入log file 中,然后到memTable. 当memTable满了或者定期刷到一个read only Immutable MemTable. 后台线程在刷入level 0. 此时level 0 可能存在重复元素。除此之外的level都不会存在。 每当level l超出了size limit,后台线程就会merge l 层和l+1 层,产生一个新的l+1 层. 读的flow:先查memtable,如果没有,从level0开始一直查下去. 如果该值不存在的话,读的效率会很低,所以一般会用到bloom filter来加速
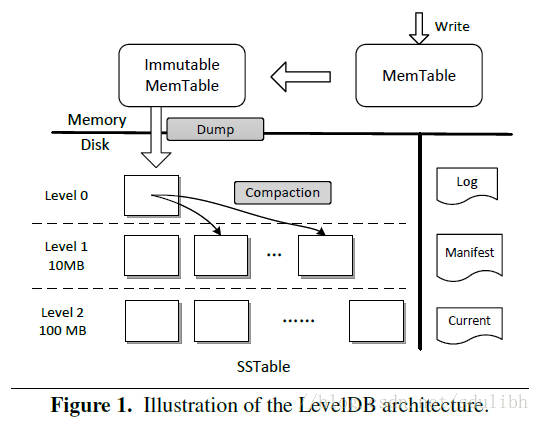
- use case: levelDB, RocksDB
- advantages
- support high write throughtput.
- support range queries.
- disadvantages
- read might slow
- compaction process can sometimes interfere with the performance of ongoing reads and writes
- If write throughput is high and compaction is not configured carefully, it can happen that compaction cannot keep up with the rate of incoming writes
B Tree
-
Introduce B tree: B-trees break the database down into fixed-size blocks or pages, traditionally 4 KB in size (sometimes bigger), and read or write one page at a time. 感觉就是一个多叉树,叶子节点存放的是page. 这个结构里面,写入操作是overwrite的, 因为中间牵扯到page split, 所以写的时候,需要额外一个 WAL(a write-ahead log), 以防写在一半的时候,数据库crash。 这只是其中一种解决办法
- use case: SQL
- advantages
- faster for read operations
- Each key exists in exactly one place in the B tree, whereas a log-structured storage engine may have multiple copies of the same key in different segments.
- disadvantages
- writes slow since overwrite data
Chapter 4
This chapter discussed several data encoding formats and their compatibility properties and several modes of dataflow.
Data encoding formats
-
Programming language–specific encodings are restricted to a single program‐ ming language and often fail to provide forward and backward compatibility.
-
Textual formats like JSON, XML, and CSV are widespread, and their compatibility depends on how you use them. e.g. JSON and XML have good support for Unicode character strings, but they don’t support binary strings. So people get around this limitation by encoding the binary data as text using Base64.
-
Binary schema–driven formats like Thrift, Protocol Buffers, and Avro allow compact, efficient encoding with clearly defined forward and backward compatibility semantics. The schemas can be useful for documentation and code genera‐ tion in statically typed languages. However, they have the downside that data needs to be decoded before it is human-readable.
Dataflow
- Databases
- RPC and REST APIs
- The RPC model tries to make a request to a remote net‐ work service look the same as calling a function or method in your programming language, within the same process. 这里书里罗列了几点local requests和网络之间call的不同.
- Message-Passing Dataflow: a difference compared to RPC is that message-passing communication is usually one-way: a sender normally doesn’t expect to receive a reply to its messages.
这章看起来还是比较轻松的,几乎没讲什么。都是一些基础概念。。过
Chapter 5
哇,这章也基本全是概念。抄一个summary吧。
why Replication
- High availability: Keeping the system running, even when one machine (or several machines, or an entire datacenter) goes down
- Disconnected operation: Allowing an application to continue working when there is a network interruption
- Latency: Placing data geographically close to users, so that users can interact with it faster
- Scalability: Being able to handle a higher volume of reads than a single machine could handle, by performing reads on replicas
Main approaches to replication:
- Single-leader replication
- Multi-leader replication
- Leaderless replication 这三种类型各有利弊,主要是考虑数据之间如何copy.
A few consistency models
- Read-after-write consistency: Users should always see data that they submitted themselves.
- Monotonic reads: After users have seen the data at one point in time, they shouldn’t later see the data from some earlier point in time.
- Consistent prefix reads: Users should see the data in a state that makes causal sense: for example, seeing a question and its reply in the correct order.
Chapter 6
Partitioning(sharding) is a way of intentionally breaking a large database down into smaller ones. The main reason for wanting to partition data is scalability
If the partitioning is unfair, it can cause:
- hot spots (nodes with disproportionately high load)
- skewed (some partitions have more data or queries than others)
Partitioning
Different ways of partitioning a large dataset into smaller subsets:
- Partitioning by Key Range
- advantages: easy for range queries
- diadvantages: certain access patterns can lead to hot spots. e.g. if index is timestamp. all data in a timespan will go to the same partition.
In this approach, partitions are typically rebalanced dynamically by splitting the range into two subranges when a partition gets too big.
- Partitioning by Hash of Key
- advantages: reduce hot spots but it cannot avoid entirely. e.g. a celebrity user with millions of followers 发生点什么新闻, 用户评论讲写入同一个key. 一个简单的解决办法,在key后面加一些random number. 但是这样做的话,read的时候需要额外的合并操作.
- disadvantages: lose a nice property of key-range partitioning
When partitioning by hash, it is common to create a fixed number of partitions in advance, to assign several partitions to each node, and to move entire parti‐ tions from one node to another when nodes are added or removed. Dynamic partitioning can also be used.
Partitioning and Secondary Indexes
-
Document-partitioned indexes (local indexes), where the secondary indexes are stored in the same partition as the primary key and value. This means that only a single partition needs to be updated on write, but a read of the secondary index requires a scatter/gather across all partitions.
-
Term-partitioned indexes (global indexes), where the secondary indexes are partitioned separately, using the indexed values. An entry in the secondary index may include records from all partitions of the primary key. When a document is written, several partitions of the secondary index need to be updated; however, a read can be served from a single partition.
Chapter 7
首先定义了什么是ACID 是一下4个词的缩写。 Atomicity, Consistency, Isolation, Durability
Weak Isolation
-
Read Committed 这个可以保证没有脏写与脏读。 实现方法: 给每行加锁读写的时候。 读的时候加锁效果不好,如果有写的情况发生,读的时候可以返回旧数据来解决问题。
-
Snapshot Isolation
一个 Read Committed 可能出现的问题,如图, 100 块钱消失了。
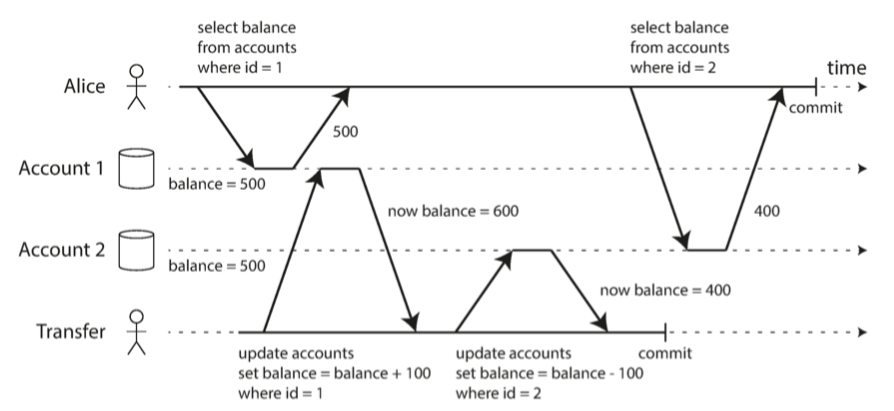
可以通过 snapshot isolation来解决。 The idea is that each transaction reads from a consistent snapshot of the database that is, the transaction sees all the data that was committed in the database at the start of the transaction. Even if the data is subsequently changed by another transaction, each transaction sees only the old data from that particular point in time. 一种实现方法叫做 multi-version concurrency control (MVCC)。 如果一个数据库只需要提供read committed级别的隔离,那么保存两个版本即可。 这样刚才的那个例子,当用户查询自己第二个账号的是返回的会是500.
- Preventing Lost updates
- 自动检查
- compare and set 就是在更新的时候的时候检测一下条件语句是否成立
- Write Skew and Phantoms 发生的场景如下, 两个事务从快照隔离读相同的数据,然后各作修改。导致一票卖两人的错误。 Phantoms 发生在事务读取符合某些搜索条件的对象。另一个客户端进行写入,影响搜索结果
Serializability
-
Actual Serial Execution:如果每个事务的执行速度非常快,并且事务吞吐量足够低,足以在单个CPU核上处理,这是一个简单而有效的选择
-
Two-Phase Locking (2PL):共享锁和排他锁, 数十年来,两阶段锁定一直是实现可序列化的标准方式,但是许多应用出于性能问题的考虑避免使用它。
-
Serializable Snapshot Isolation (SSI): 一个相当新的算法,避免了先前方法的大部分缺点。它使用乐观的方法,允许事务执行而无需阻塞。当一个事务想要提交时,它会进行检查,如果执行不可序列化,事务就会被中止。